Fast UTF-8 validation with Range algorithm (NEON+SSE4+AVX2)
This is a brand new algorithm to leverage SIMD for fast UTF-8 string validation. Both NEON(armv8a) and SSE4 versions are implemented. AVX2 implementation contributed by ioioioio.
Four UTF-8 validation methods are compared on both x86 and Arm platforms. Benchmark result shows range base algorithm is the best solution on Arm, and achieves same performance as Lemire's approach on x86.
- Range based algorithm
- range-neon.c: NEON version
- range-sse.c: SSE4 version
- range-avx2.c: AVX2 version
- range2-neon.c, range2-sse.c: Process two blocks in one iteration
- Lemire's SIMD implementation
- lemire-sse.c: SSE4 version
- lemire-avx2.c: AVX2 version
- lemire-neon.c: NEON porting
- naive.c: Naive UTF-8 validation byte by byte
- lookup.c: Lookup-table method
About the code
- Run “make” to build. Built and tested with gcc-7.3.
- Run “./utf8” to see all command line options.
- Benchmark
- Run “./utf8 bench” to bechmark all algorithms with default test file.
- Run “./utf8 bench size NUM” to benchmark specified string size.
- Run “./utf8 test” to test all algorithms with positive and negative test cases.
- To benchmark or test specific algorithm, run something like “./utf8 bench range”.
Benchmark result (MB/s)
Method
- Generate UTF-8 test buffer per test file or buffer size.
- Call validation sub-routines in a loop until 1G bytes are checked.
- Calculate speed(MB/s) of validating UTF-8 strings.
NEON(armv8a)
| Test case | naive | lookup | lemire | range | range2 |
|---|
| UTF-demo.txt | 562.25 | 412.84 | 1198.50 | 1411.72 | 1579.85 |
| 32 bytes | 651.55 | 441.70 | 891.38 | 1003.95 | 1043.58 |
| 33 bytes | 660.00 | 446.78 | 588.77 | 1009.31 | 1048.12 |
| 129 bytes | 771.89 | 402.55 | 938.07 | 1283.77 | 1401.76 |
| 1K bytes | 811.92 | 411.58 | 1188.96 | 1398.15 | 1560.23 |
| 8K bytes | 812.25 | 412.74 | 1198.90 | 1412.18 | 1580.65 |
| 64K bytes | 817.35 | 412.24 | 1200.20 | 1415.11 | 1583.86 |
| 1M bytes | 815.70 | 411.93 | 1200.93 | 1415.65 | 1585.40 |
SSE4(E5-2650)
| Test case | naive | lookup | lemire | range | range2 |
|---|
| UTF-demo.txt | 753.70 | 310.41 | 3954.74 | 3945.60 | 3986.13 |
| 32 bytes | 1135.76 | 364.07 | 2890.52 | 2351.81 | 2173.02 |
| 33 bytes | 1161.85 | 376.29 | 1352.95 | 2239.55 | 2041.43 |
| 129 bytes | 1161.22 | 322.47 | 2742.49 | 3315.33 | 3249.35 |
| 1K bytes | 1310.95 | 310.72 | 3755.88 | 3781.23 | 3874.17 |
| 8K bytes | 1348.32 | 307.93 | 3860.71 | 3922.81 | 3968.93 |
| 64K bytes | 1301.34 | 308.39 | 3935.15 | 3973.50 | 3983.44 |
| 1M bytes | 1279.78 | 309.06 | 3923.51 | 3953.00 | 3960.49 |
Range algorithm analysis
Basic idea:
- Load 16 bytes
- Leverage SIMD to calculate value range for each byte efficiently
- Validate 16 bytes at once
UTF-8 coding format
http://www.unicode.org/versions/Unicode6.0.0/ch03.pdf, page 94
Table 3-7. Well-Formed UTF-8 Byte Sequences
| Code Points | First Byte | Second Byte | Third Byte | Fourth Byte |
|---|
| U+0000..U+007F | 00..7F | | | |
| U+0080..U+07FF | C2..DF | 80..BF | | |
| U+0800..U+0FFF | E0 | A0..BF | 80..BF | |
| U+1000..U+CFFF | E1..EC | 80..BF | 80..BF | |
| U+D000..U+D7FF | ED | 80..9F | 80..BF | |
| U+E000..U+FFFF | EE..EF | 80..BF | 80..BF | |
| U+10000..U+3FFFF | F0 | 90..BF | 80..BF | 80..BF |
| U+40000..U+FFFFF | F1..F3 | 80..BF | 80..BF | 80..BF |
| U+100000..U+10FFFF | F4 | 80..8F | 80..BF | 80..BF |
To summarise UTF-8 encoding:
- Depending on First Byte, one legal character can be 1, 2, 3, 4 bytes
- For First Byte within C0..DF, character length = 2
- For First Byte within E0..EF, character length = 3
- For First Byte within F0..F4, character length = 4
- C0, C1, F5..FF are not allowed
- Second,Third,Fourth Bytes must lie in 80..BF.
- There are four special cases for Second Byte, shown bold italic in above table.
Range table
Range table maps range index 0 ~ 15 to minimal and maximum values allowed. Our task is to observe input string, find the pattern and set correct range index for each byte, then validate input string.
| Index | Min | Max | Byte type |
|---|
| 0 | 00 | 7F | First Byte, ASCII |
| 1,2,3 | 80 | BF | Second, Third, Fourth Bytes |
| 4 | A0 | BF | Second Byte after E0 |
| 5 | 80 | 9F | Second Byte after ED |
| 6 | 90 | BF | Second Byte after F0 |
| 7 | 80 | 8F | Second Byte after F4 |
| 8 | C2 | F4 | First Byte, non-ASCII |
| 9..15(NEON) | FF | 00 | Illegal: unsigned char >= 255 && unsigned char <= 0 |
| 9..15(SSE) | 7F | 80 | Illegal: signed char >= 127 && signed char <= -128 |
Calculate byte ranges (ignore special cases)
Ignoring the four special cases(E0,ED,F0,F4), how should we set range index for each byte?
- Set range index to 0(00..7F) for all bytes by default
- Find non-ASCII First Byte (C0..FF), set their range index to 8(C2..F4)
- For First Byte within C0..DF, set next byte's range index to 1(80..BF)
- For First Byte within E0..EF, set next two byte's range index to 2,1(80..BF) in sequence
- For First Byte within F0..FF, set next three byte's range index to 3,2,1(80..BF) in sequence
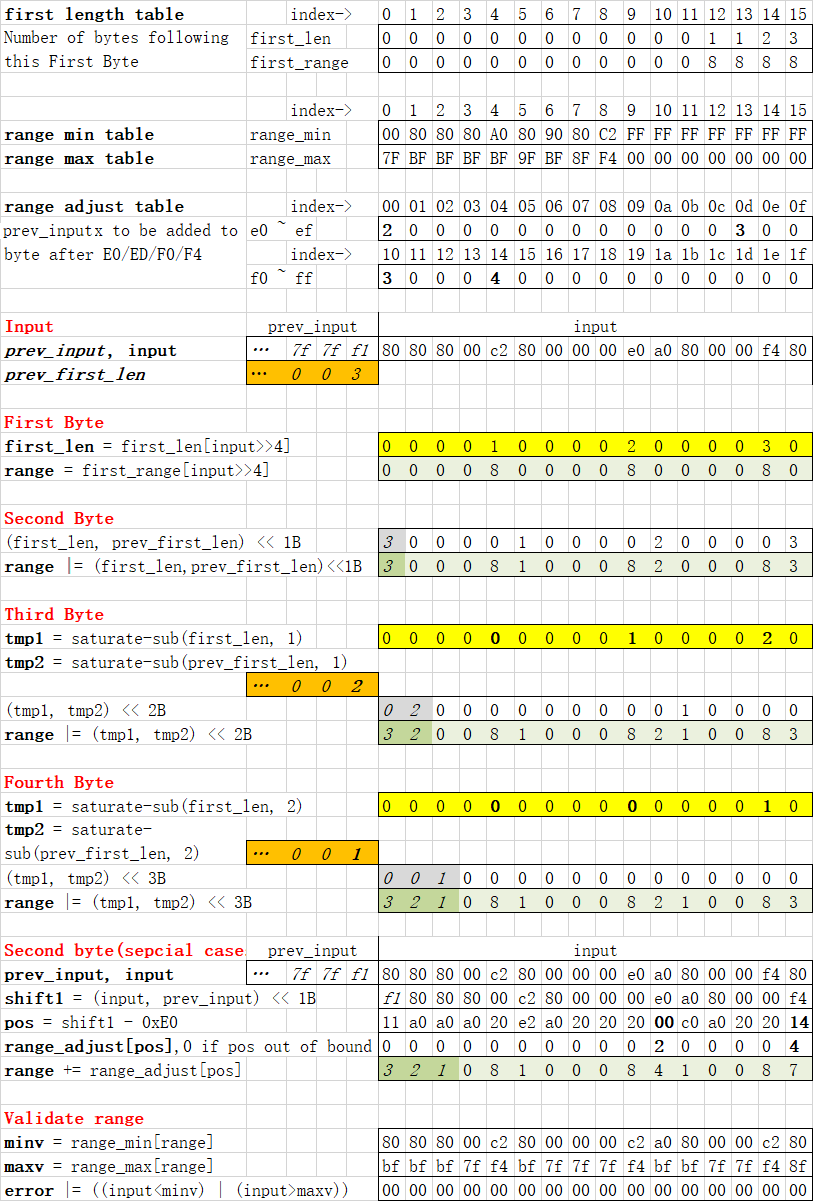
To implement above operations efficiently with SIMD:
- For 16 input bytes, use lookup table to map C0..DF to 1, E0..EF to 2, F0..FF to 3, others to 0. Save to first_len.
- Map C0..FF to 8, we get range indices for First Byte.
- Shift first_len one byte, we get range indices for Second Byte.
- Saturate substract first_len by one(3->2, 2->1, 1->0, 0->0), then shift two bytes, we get range indices for Third Byte.
- Saturate substract first_len by two(3->1, 2->0, 1->0, 0->0), then shift three bytes, we get range indices for Fourth Byte.
Example(assume no previous data)
| Input | F1 | 80 | 80 | 80 | 80 | C2 | 80 | 80 | ... |
|---|
| first_len | 3 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | ... |
| First Byte | 8 | 0 | 0 | 0 | 0 | 8 | 0 | 0 | ... |
| Second Byte | 0 | 3 | 0 | 0 | 0 | 0 | 1 | 0 | ... |
| Third Byte | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | ... |
| Fourth Byte | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | ... |
| Range index | 8 | 3 | 2 | 1 | 0 | 8 | 1 | 0 | ... |
Range_index = First_Byte | Second_Byte | Third_Byte | Fourth_Byte
Error handling
- C0,C1,F5..FF are not included in range table and will always be detected.
- Illegal 80..BF will have range index 0(00..7F) and be detected.
- Based on First Byte, according Second, Third and Fourth Bytes will have range index 1/2/3, to make sure they must lie in 80..BF.
- If non-ASCII First Byte overlaps, above algorithm will set range index of the latter First Byte to 9,10,11, which are illegal ranges. E.g, Input = F1 80 C2 90 --> Range index = 8 3 10 1, where 10 indicates error. See table below.
Overlapped non-ASCII First Byte
| Input | F1 | 80 | C2 | 90 |
|---|
| first_len | 3 | 0 | 1 | 0 |
| First Byte | 8 | 0 | 8 | 0 |
| Second Byte | 0 | 3 | 0 | 1 |
| Third Byte | 0 | 0 | 2 | 0 |
| Fourth Byte | 0 | 0 | 0 | 1 |
| Range index | 8 | 3 | 10 | 1 |
Adjust Second Byte range for special cases
Range index adjustment for four special cases
| First Byte | Second Byte | Before adjustment | Correct index | Adjustment |
|---|
| E0 | A0..BF | 2 | 4 | 2 |
| ED | 80..9F | 2 | 5 | 3 |
| F0 | 90..BF | 3 | 6 | 3 |
| F4 | 80..8F | 3 | 7 | 4 |
Range index adjustment can be reduced to below problem:
Given 16 bytes, replace E0 with 2, ED with 3, F0 with 3, F4 with 4, others with 0.
A naive SIMD approach:
- Compare 16 bytes with E0, get the mask for eacy byte (FF if equal, 00 otherwise)
- And the mask with 2 to get adjustment for E0
- Repeat step 1,2 for ED,F0,F4
At least eight operations are required for naive approach.
Observing special bytes(E0,ED,F0,F4) are close to each other, we can do much better using lookup table.
NEON
NEON tbl instruction is very convenient for table lookup:
- Table can be up to 16x4 bytes in size
- Return zero if index is out of range
Leverage these features, we can solve the problem with as few as two operations:
- Precreate a 16x2 lookup table, where table[0]=2, table[13]=3, table[16]=3, table[20]=4, table[others]=0.
- Substract input bytes with E0 (E0 -> 0, ED -> 13, F0 -> 16, F4 -> 20).
- Use the substracted byte as index of lookup table and get range adjustment directly.
- For indices less than 32, we get zero or required adjustment value per input byte
- For out of bound indices, we get zero per
tbl behaviour
SSE
SSE pshufb instruction is not as friendly as NEON tbl in this case:
- Table can only be 16 bytes in size
- Out of bound indices are handled this way:
- If 7-th bit of index is 0, least four bits are used as index (E.g, index 0x73 returns 3rd element)
- If 7-th bit of index is 1, return 0 (E.g, index 0x83 returns 0)
We can still leverage these features to solve the problem in five operations:
- Precreate two tables:
- table_df[1] = 2, table_df[14] = 3, table_df[others] = 0
- table_ef[1] = 3, table_ef[5] = 4, table_ef[others] = 0
- Substract input bytes with EF (E0 -> 241, ED -> 254, F0 -> 1, F4 -> 5) to get the temporary indices
- Get range index for E0,ED
- Saturate substract temporary indices with 240 (E0 -> 1, ED -> 14, all values below 240 becomes 0)
- Use substracted indices to look up table_df, get the correct adjustment
- Get range index for F0,F4
- Saturate add temporary indices with 112(0x70) (F0 -> 0x71, F4 -> 0x75, all values above 16 will be larger than 128(7-th bit set))
- Use added indices to look up table_ef, get the correct adjustment (index 0x71,0x75 returns 1st,5th elements, per
pshufb behaviour)
Error handling
- For overlapped non-ASCII First Byte, range index before adjustment is 9,10,11. After adjustment (adds 2,3,4 or 0), the range index will be 9 to 15, which is still illegal in range table. So the error will be detected.
Handling remaining bytes
For remaining input less than 16 bytes, we will fallback to naive byte by byte approach to validate them, which is actually faster than SIMD processing.
- Look back last 16 bytes buffer to find First Byte. At most three bytes need to look back. Otherwise we either happen to be at character boundray, or there are some errors we already detected.
- Validate string byte by byte starting from the First Byte.
Tests
It's necessary to design test cases to cover corner cases as more as possible.
Positive cases
- Prepare correct characters
- Validate correct characters
- Validate long strings
- Round concatenate characters starting from first character to 1024 bytes
- Validate 1024 bytes string
- Shift 1 byte, validate 1025 bytes string
- Shift 2 bytes, Validate 1026 bytes string
- ...
- Shift 16 bytes, validate 1040 bytes string
- Repeat step3, test buffer starting from second character
- Repeat step3, test buffer starting from third character
- ...
Negative cases
- Prepare bad characters and bad strings
- Bad character
- Bad character cross 16 bytes boundary
- Bad character cross last 16 bytes and remaining bytes boundary
- Test long strings
- Prepare correct long strings same as positive cases
- Append bad characters
- Shift one byte for each iteration
- Validate each shift
Code breakdown
Below table shows how 16 bytes input are processed step by step. See range-neon.c for according code.